The difficulty with appearance based localization (as it is used in RTAB-MAP) is that it only uses 2D feature points in the video images for finding an location. Here's an example of an image where 2D feature points were found. The feature points are found at light gradients i.e. where there is a change from a dark to light pixel or vice versa:

These 2D feature points are saved in the map at each location. For localization the same feature points have to be detected. A small light change and the number of feature points changes dramatically. So in other words, because it's using the color 2D information of the pixels it's important the location looks always the same. 'maplab' (I did not try it) seem to use appearance based localization too?
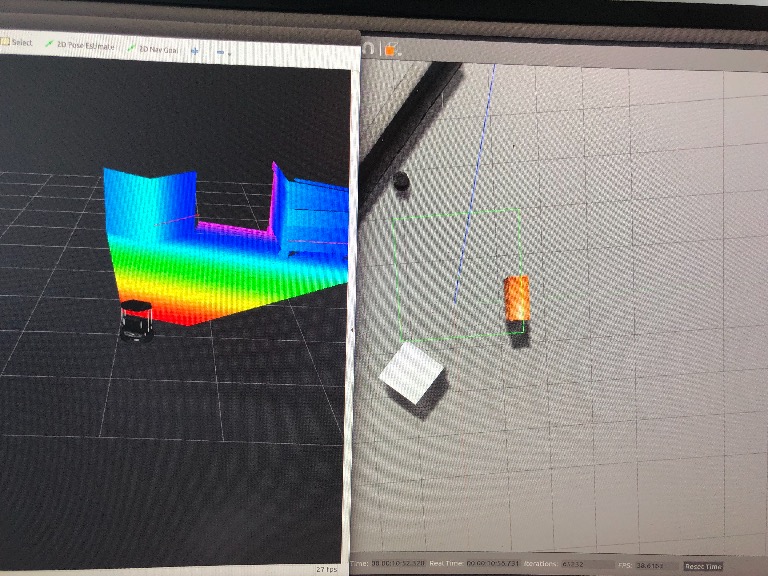
' http://wiki.ros.org/humanoid_localization ' (I did not try it) may work with the Realsense ( video1 , video2 ) and it uses geometric based localization so uses the full 3D information (including depth) of the pixels. This may need more computation time. And because it's using the 3D information of the pixels, the 3rd pixel information (depth) must be always the same (not be noisy). Here, the particle filter (or monte carlo method) is used internally to continously generate and filter correlation results.
I'll do some simulations here with Gazebo (it can simulate many sensors including a Realsense) and different ROS packages before working with the real sensors and will let you know my results.
Attachment: https://forum.ardumower.de/data/media/kunena/attachments/905/feature_points.png/
These 2D feature points are saved in the map at each location. For localization the same feature points have to be detected. A small light change and the number of feature points changes dramatically. So in other words, because it's using the color 2D information of the pixels it's important the location looks always the same. 'maplab' (I did not try it) seem to use appearance based localization too?
' http://wiki.ros.org/humanoid_localization ' (I did not try it) may work with the Realsense ( video1 , video2 ) and it uses geometric based localization so uses the full 3D information (including depth) of the pixels. This may need more computation time. And because it's using the 3D information of the pixels, the 3rd pixel information (depth) must be always the same (not be noisy). Here, the particle filter (or monte carlo method) is used internally to continously generate and filter correlation results.
I'll do some simulations here with Gazebo (it can simulate many sensors including a Realsense) and different ROS packages before working with the real sensors and will let you know my results.
Attachment: https://forum.ardumower.de/data/media/kunena/attachments/905/feature_points.png/
Zuletzt bearbeitet von einem Moderator:
")









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}