Hallo zusammen,
ich eröffne heute mal einen Thread wie ich die KI meines Roboters realisiert habe. Möglicherweise kann der eine oder ander ja einige Anregungen in dieser Hinsicht verwenden oder auch mir noch einige Tipps geben, wie ich die Sache verbessern kann. Aktuell habe ich nur das Mähverhalten abgebildet mit Perimetererkennung und Rundumbumper und das auch noch nicht bis zum Ende, da ich erst nächstes Jahr den Robbi wieder auf die Wiese schicke.
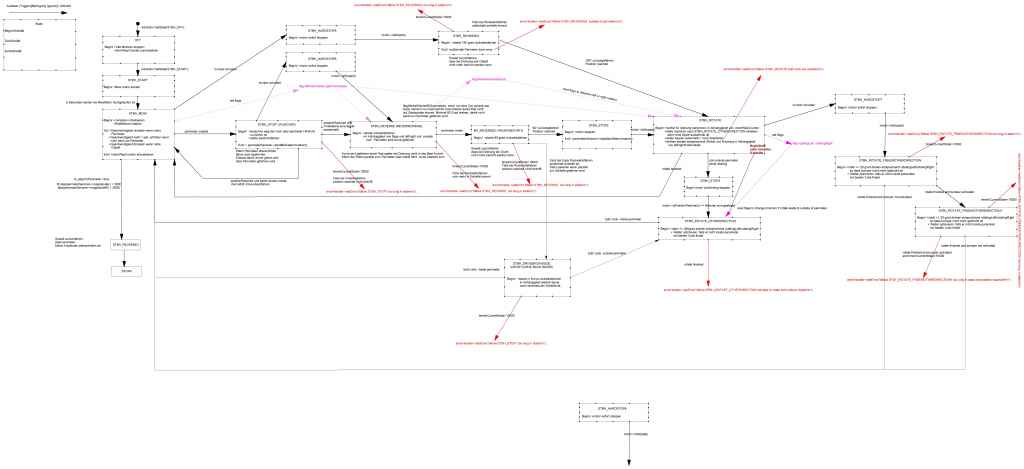
Als ich 2013 meinen ersten Rasenroboter gebaut habe, habe ich einen Subsumtion Algorithmus verwendet. Den aktuellen Roboter wollte ich dann mit einer Hierarchical Finite State Machine realisieren. Ich habe bezüglich der FSM ein sehr einfaches C++ Template gefunden und die Umsetzung des Verhaltens in das Programm war relative einfach. Dann kam aber der Zeitpunkt, wo ich den Rundumbumper eingebaut habe. Die Anpassung der FSM wurde komplexer, da ich zu diesem Zeitpunkt davon Ausging das in jedem State der Perimeter überfahren werden kann oder der Bumper aktiviert werden kann sowie dass ich das Mähverhalten nicht in unterschiedliche FSM aufteilen wollte . Daher habe ich eine andere Lösung gesucht und bin dann auf den BehavoiurTree gestossen. Diese Art eine KI zu programmieren wird in der Spieleindustrie bereits seit über 10 Jahren eingesetzt und das war der Anlass für mich mal zu erforschen was denn dahinter steckt und wie ich dieses in meinen Robbi einbringen kann.
Ich will hier nicht erklären, was BehaviourTrees sind. Dazu gibt es genug Artikel im Netz wie hier zum Beispiel: http://www.gamasutra.com/blogs/ChrisSimpson/20140717/221339/Behavior_trees_for_AI_How_they_work.php http://guineashots.com/2014/07/25/an-introduction-to-behavior-trees-part-1/
Nachdem ich mir diverse Artikle bezüglich Behavior Trees durchgelesen habe, ging es an die Umsetzung. Da es keine wirklich für mich 100%ig verwendbare Library gab, habe ich mir diese selber zusammen geschrieben. D.h. aus unterschiedlichen Quellen zusammengeführt und dann noch meinen Senf dazugegeben.
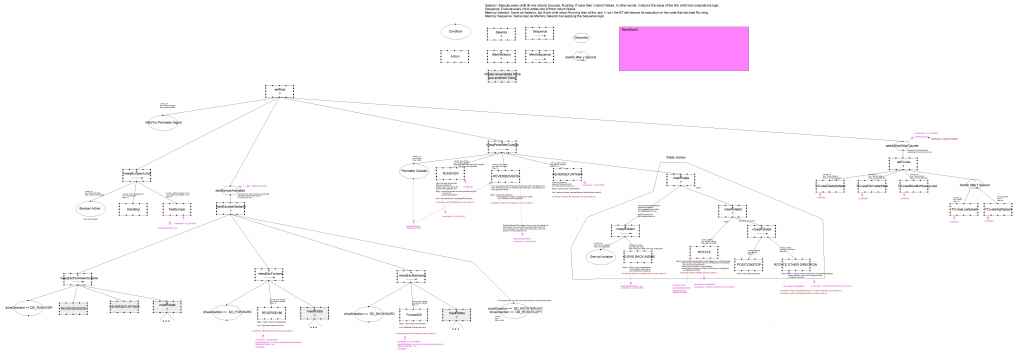
Die Umsetzung des Verhaltens von einer FSM zum Behaviour Tree hat sich am Anfang etwas schwierig gestalte, da der gedankliche Ansatz ein anderer war. Teilweise habe ich schon gezweifelt, ob die Nutzung des BHT für mich zu Aufwändig ist, da die Umsetzung mit der FSM dagegen relative einfach war - oder vielleicht doch nur eine Sache der Gewohnheit? Na ja, es wurde immer besser. Ich habe erst das Cruise Verhalten programmiert, dann das Perimeter Verhalten. Bei dem Bumperverhalten fehlte mir anfänglich die Idee, da ich diese ja bisher parallel zu dem Perimeterverhalten in der FSM geprüft habe. Ich habe mich daher erstmal für eine Subsumption Ansatz entschieden. D.h. der Bumper hat Priorität vor dem Perimeter und wird als erstes überprüft und abgehandelt, wenn ein Bumperereignis auftritt. Als ich dann die Escape Verhalten für die einzelnen Bumpereinschläge programmiert habe, habe ich als erstes den Vorteil dieser Art der Programmierung gesehen. Wenn man erstmal die Gedankengänge geändert hat von einer FSM auf den Behaviour Tree umzusteigen ist die Umsetzung genau so einfach. Der aktuelle Vorteil liegt aber in der Wiederverwendbarkeint der Nodes mit nur einem Befehl. So kann ich an einem Punkt eine Node einfügen die ich bereits woanders programmiert habe oder ich kann einen ganzen Zweig einfügen ohne Aufwand. Man kann dies sehr schön an dem mselRotate Zweig sehen in dem angefügten Bild.
Mein gesamt Programm habe ich so aufgebaut, dass es Service Threads gibt, die die Sensoren auslesen, die Motoren steuern oder die Position anfahren. Diese laufen im "Hindergrund". Die Services stellen ihre Dienste auf einem Blackboard zur Verfügung. Dieses wird in der tick() Funktion welche jedes Node implementiert hat übergeben.
Ich habe mal die alte FSM und den neuen Behaviour Tree rangehängt. Falls es jemanden gibt der mehr Infos haben möchte oder den Code benötigt, einfach sagen. Wenn jemand sowas schon mal umgesetzt hat, wäre gut wenn er mir seine Infos zukommen lassen könnte.
ich eröffne heute mal einen Thread wie ich die KI meines Roboters realisiert habe. Möglicherweise kann der eine oder ander ja einige Anregungen in dieser Hinsicht verwenden oder auch mir noch einige Tipps geben, wie ich die Sache verbessern kann. Aktuell habe ich nur das Mähverhalten abgebildet mit Perimetererkennung und Rundumbumper und das auch noch nicht bis zum Ende, da ich erst nächstes Jahr den Robbi wieder auf die Wiese schicke.
Als ich 2013 meinen ersten Rasenroboter gebaut habe, habe ich einen Subsumtion Algorithmus verwendet. Den aktuellen Roboter wollte ich dann mit einer Hierarchical Finite State Machine realisieren. Ich habe bezüglich der FSM ein sehr einfaches C++ Template gefunden und die Umsetzung des Verhaltens in das Programm war relative einfach. Dann kam aber der Zeitpunkt, wo ich den Rundumbumper eingebaut habe. Die Anpassung der FSM wurde komplexer, da ich zu diesem Zeitpunkt davon Ausging das in jedem State der Perimeter überfahren werden kann oder der Bumper aktiviert werden kann sowie dass ich das Mähverhalten nicht in unterschiedliche FSM aufteilen wollte . Daher habe ich eine andere Lösung gesucht und bin dann auf den BehavoiurTree gestossen. Diese Art eine KI zu programmieren wird in der Spieleindustrie bereits seit über 10 Jahren eingesetzt und das war der Anlass für mich mal zu erforschen was denn dahinter steckt und wie ich dieses in meinen Robbi einbringen kann.
Ich will hier nicht erklären, was BehaviourTrees sind. Dazu gibt es genug Artikel im Netz wie hier zum Beispiel: http://www.gamasutra.com/blogs/ChrisSimpson/20140717/221339/Behavior_trees_for_AI_How_they_work.php http://guineashots.com/2014/07/25/an-introduction-to-behavior-trees-part-1/
Nachdem ich mir diverse Artikle bezüglich Behavior Trees durchgelesen habe, ging es an die Umsetzung. Da es keine wirklich für mich 100%ig verwendbare Library gab, habe ich mir diese selber zusammen geschrieben. D.h. aus unterschiedlichen Quellen zusammengeführt und dann noch meinen Senf dazugegeben.
Die Umsetzung des Verhaltens von einer FSM zum Behaviour Tree hat sich am Anfang etwas schwierig gestalte, da der gedankliche Ansatz ein anderer war. Teilweise habe ich schon gezweifelt, ob die Nutzung des BHT für mich zu Aufwändig ist, da die Umsetzung mit der FSM dagegen relative einfach war - oder vielleicht doch nur eine Sache der Gewohnheit? Na ja, es wurde immer besser. Ich habe erst das Cruise Verhalten programmiert, dann das Perimeter Verhalten. Bei dem Bumperverhalten fehlte mir anfänglich die Idee, da ich diese ja bisher parallel zu dem Perimeterverhalten in der FSM geprüft habe. Ich habe mich daher erstmal für eine Subsumption Ansatz entschieden. D.h. der Bumper hat Priorität vor dem Perimeter und wird als erstes überprüft und abgehandelt, wenn ein Bumperereignis auftritt. Als ich dann die Escape Verhalten für die einzelnen Bumpereinschläge programmiert habe, habe ich als erstes den Vorteil dieser Art der Programmierung gesehen. Wenn man erstmal die Gedankengänge geändert hat von einer FSM auf den Behaviour Tree umzusteigen ist die Umsetzung genau so einfach. Der aktuelle Vorteil liegt aber in der Wiederverwendbarkeint der Nodes mit nur einem Befehl. So kann ich an einem Punkt eine Node einfügen die ich bereits woanders programmiert habe oder ich kann einen ganzen Zweig einfügen ohne Aufwand. Man kann dies sehr schön an dem mselRotate Zweig sehen in dem angefügten Bild.
Mein gesamt Programm habe ich so aufgebaut, dass es Service Threads gibt, die die Sensoren auslesen, die Motoren steuern oder die Position anfahren. Diese laufen im "Hindergrund". Die Services stellen ihre Dienste auf einem Blackboard zur Verfügung. Dieses wird in der tick() Funktion welche jedes Node implementiert hat übergeben.
Ich habe mal die alte FSM und den neuen Behaviour Tree rangehängt. Falls es jemanden gibt der mehr Infos haben möchte oder den Code benötigt, einfach sagen. Wenn jemand sowas schon mal umgesetzt hat, wäre gut wenn er mir seine Infos zukommen lassen könnte.
")